const team = oma.createTeam('api-team', { agents })// one call: goal → task DAG → resultconst result = await oma.runTeam(team,"Build a REST API for a todo list: design the data model and routes, implement the CRUD endpoints, generate a test suite, and review it for security.",)
An agent runtime, not a graph builder.
Goal-first, not graph-first. You describe the outcome; OMA owns the decomposition, the parallelism, and the synthesis.
You pass a goal, not a graph. A coordinator agent decomposes it into a task DAG, parallelizes independent nodes, and synthesizes the result.
Each agent names its own model — Anthropic, OpenAI, a local Ollama, or a self-hosted endpoint — and they cooperate inside a single team.
An agent gets only the tools it lists. Connect Model Context Protocol servers to expose external systems under the same opt-in contract.
Stream tokens and node-state transitions as the DAG fills, or await a typed, schema-validated object at the end of the run.
One thinking config maps to Anthropic thinking, Gemini thinkingConfig, and OpenAI reasoning_effort — reasoning streams as events, with opt-in preservation across a provider switch.
import { OpenMultiAgent, type AgentConfig } from '@open-multi-agent/core'const agents: AgentConfig[] = [{ name: 'architect', model: 'claude-sonnet-4-6', tools: ['file_write'] },{ name: 'developer', model: 'claude-sonnet-4-6', tools: ['bash', 'file_read', 'file_write', 'file_edit'] },{ name: 'reviewer', model: 'claude-sonnet-4-6', tools: ['file_read', 'grep'] },]const oma = new OpenMultiAgent({ defaultModel: 'claude-sonnet-4-6' })const team = oma.createTeam('api-team', { name: 'api-team', agents })// coordinator plans the DAG, runs independents in parallel, synthesizesconst result = await oma.runTeam(team, 'Create a REST API for a todo list')
Built to run in production.
Handing real work to autonomous agents raises three fair questions: do they run off the rails, burn the budget, or fail where you can't see it? Each one has an answer in the API.
Inspect the plan before any agent runs with onPlanReady, then approve each round with onApproval. A proposer→judge pass (runConsensus) has one agent check another's output, and loop detection halts an agent that starts repeating itself.
Route planning to a flagship model and the leaf tasks to cheap ones with modelRouting. maxTokenBudget caps a run's spend — cross it and the orchestrator stops issuing calls instead of running up the bill.
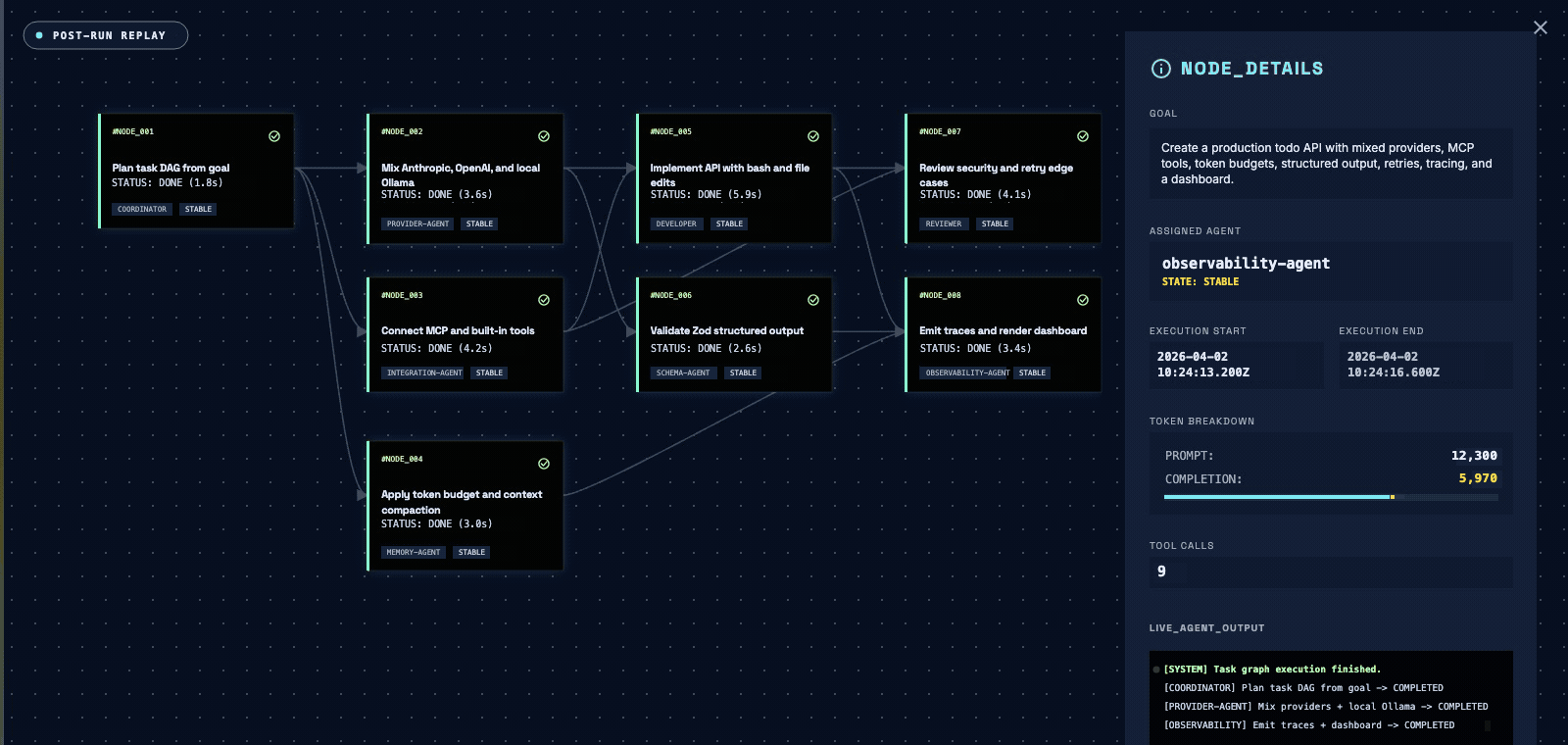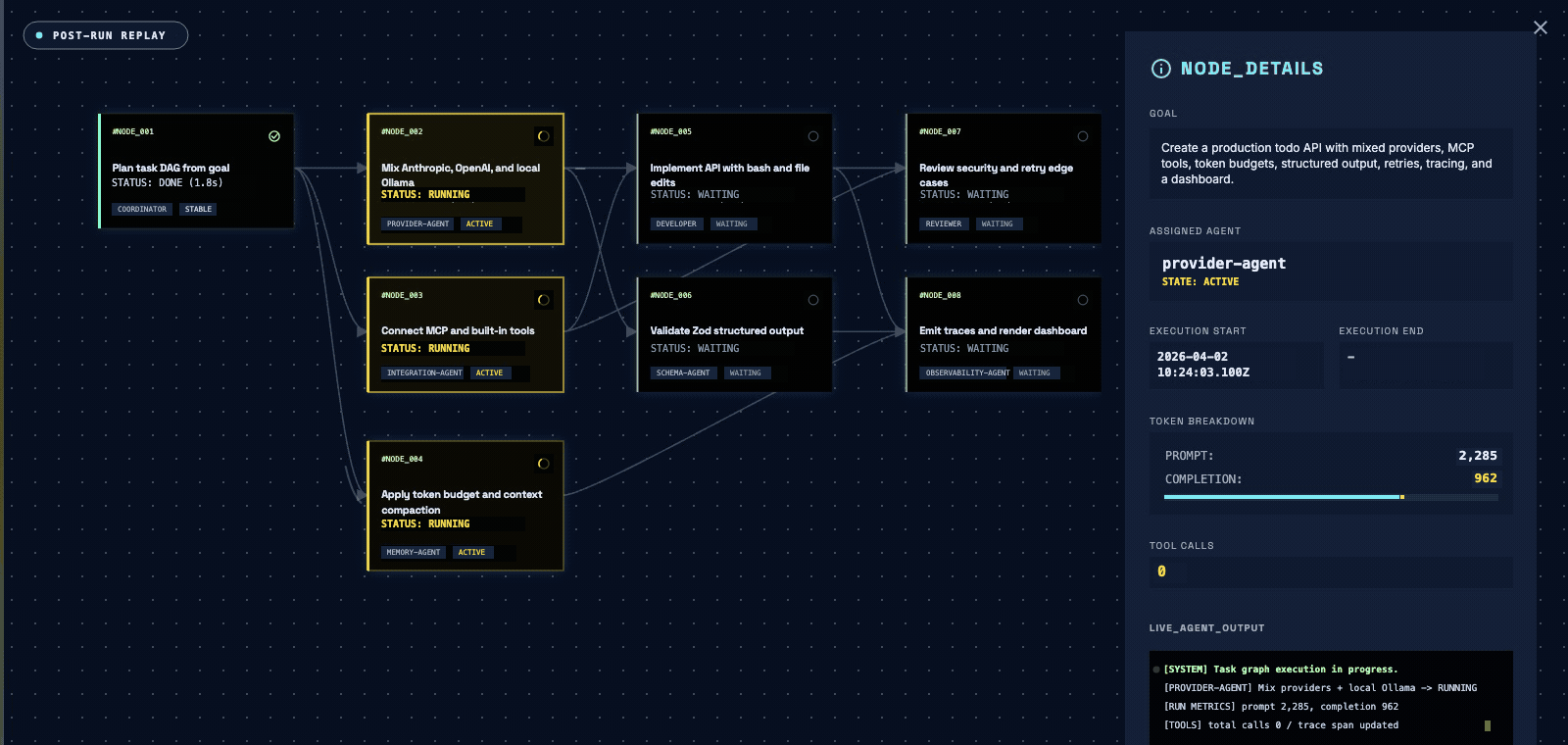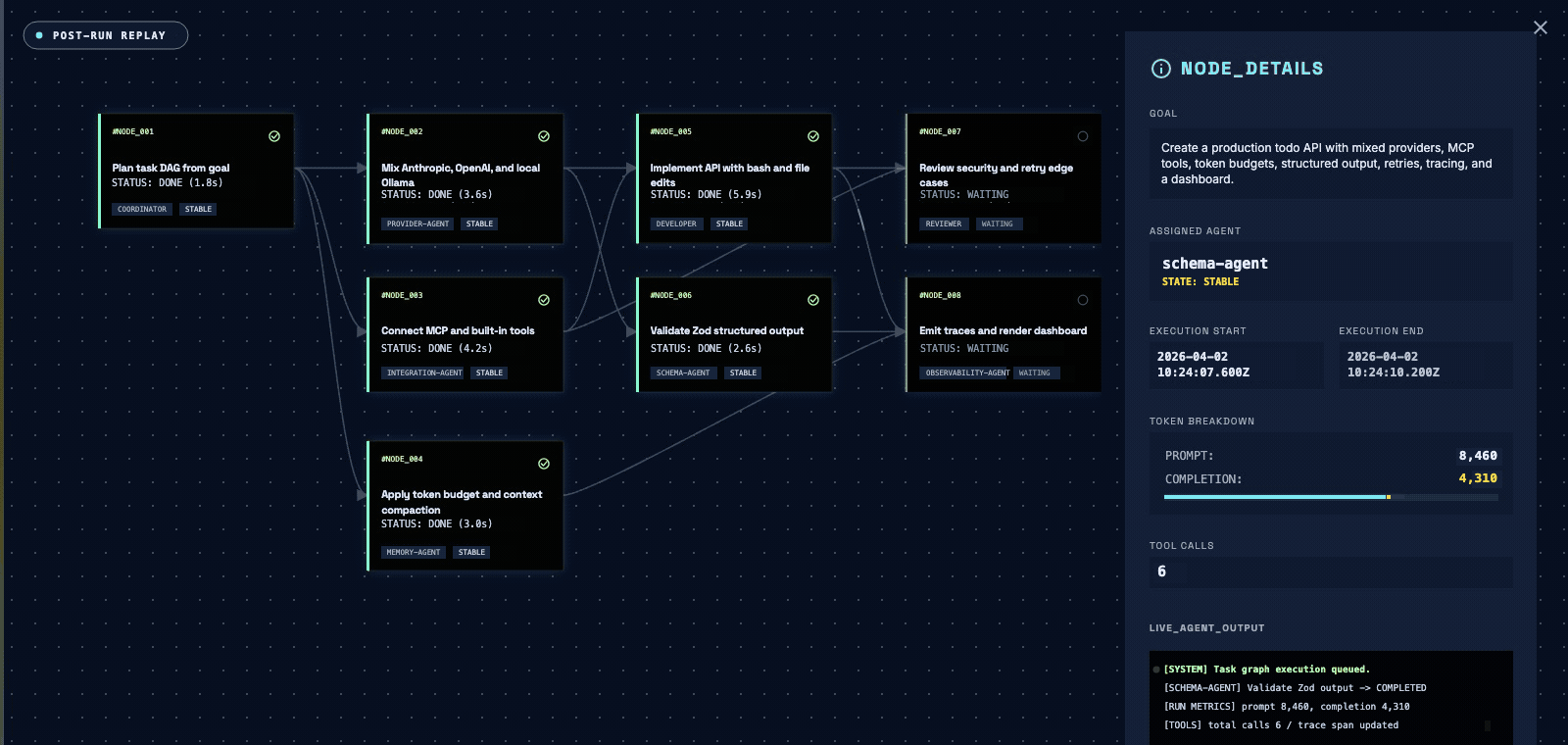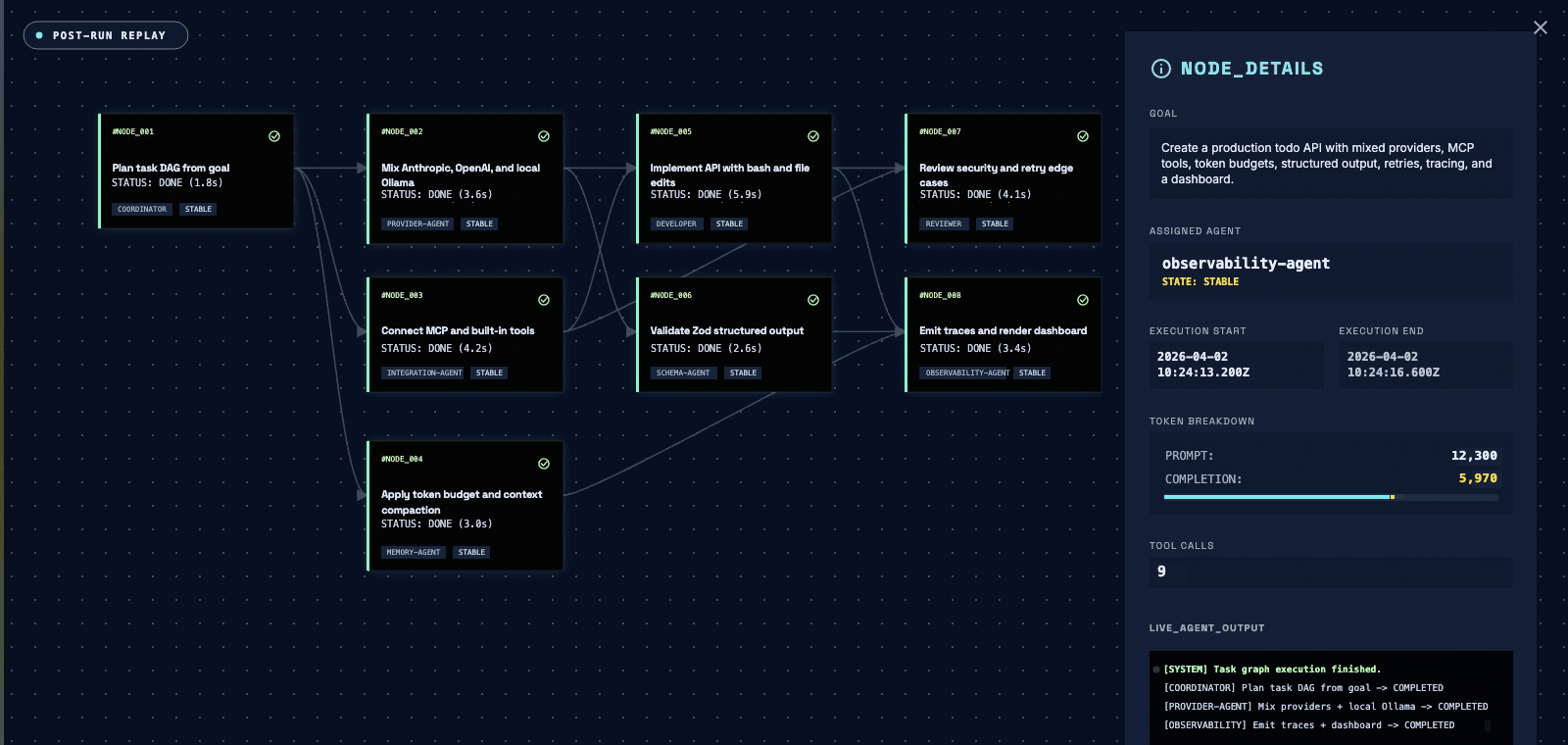
Stream every LLM and tool call to your tracing stack with onTrace, or open a self-contained HTML dashboard after the run (oma run --dashboard). Checkpoints resume a crashed run from its last completed task, and secrets are redacted from traces and dashboards on a best-effort basis.
Three workflows worth a team.
Each is a single goal that benefits from parallel, multi-model decomposition — exactly what the coordinator is built for.
One goal — “flag risk in this MSA” — fans out to agents reading clauses, cross-checking a policy library, and drafting redlines in parallel.
Agents pull from different sources via MCP, each on the model that fits — cheap-local for scraping, frontier for analysis — and reconcile findings.
Logs, metrics, and the deploy timeline are investigated as parallel nodes; a reviewer agent synthesizes cause and contributing factors.
Works with your stack.
OMA composes with the providers, protocols, and servers already in your backend — no platform to migrate to.
Already running in the wild.
Open source and MIT-licensed, with a growing ecosystem of projects and integrations. Star, fork, and contributor counts read straight from the repo at build time.
WordPress security analysis platform. Runs OMA built-in tools (bash, file ops, grep) inside a Docker runtime.
“Git for AI memory” — shared memory across agents with conflict detection, via an OMA MemoryStore + ToolRegistry toolkit.
Sidecar that detects cross-run delegation cycles, repetition, and rate bursts.
Mechanism, not marketing.
How the runtime actually behaves. The full reference lives in the docs.